






























La Curva de Aprendizaje, parte 3: evolucionando los datos de IA de buenos a excelentes
Samsung Research en Vietnam es parte de una serie sobre las personas y las innovaciones que permiten que la IA móvil mejore más vidas

Samsung es pionera en experiencias premium de IA móvil. Para saber cómo Galaxy AI está maximizando el potencial de sus usuarios, visitamos los centros Samsung Research en todo el mundo. Galaxy AI, que ahora admite 16 idiomas, permite que más personas amplíen sus capacidades lingüísticas, incluso sin conexión, gracias a la traducción en el dispositivo con funciones como Traducción Simultánea, Intérprete, Asistente de Notas y Asistente de Navegación. Recientemente, visitamos Jordania para conocer las complejidades del desarrollo de un modelo de IA para el árabe, un idioma con muchos dialectos. Esta vez, vamos a Vietnam para explorar cómo se preparan los datos para entrenar modelos de IA.
¿Cuál es la diferencia entre fantasma, tumba y madre en vietnamita? Para una lengua hablada por 97 millones de personas en todo el mundo, es muy poco. Cada palabra se traduce como “ma”, “mả” y “má”, respectivamente, y solo se puede distinguir por el tono. Esto ilustra lo difícil que puede ser para los modelos de IA aprender un idioma, considerando que no pueden reconocer de primera mano el contexto y las emociones de las conversaciones ni las intenciones de quienes hablan.
El Instituto de Investigación y Desarrollo de Samsung (SRV) de Vietnam utilizó datos finamente revisados para ayudar a que su modelo de IA reconociera adecuadamente incluso las diferencias más sutiles en el lenguaje.
La calidad de los datos utilizados afecta directamente la precisión del reconocimiento automático de voz (ASR), la traducción automática neuronal (NMT) y la conversión de texto a voz (TTS), procesos que ayudan las funciones de Galaxy AI como Traducción Simultánea, Intérprete, Asistente de Escritura y Asistente de Navegación a romper las barreras del idioma.
Un tifón de desafíos
"El vietnamita es un idioma complejo y diverso con expresiones ricas, muchas de las cuales son difíciles de capturar", dice Ngô Hồng Thái, líder de NMT en SRV. De los 16 idiomas que admite Galaxy AI, el vietnamita fue particularmente difícil de desarrollar.

"Personalmente, ¡crear un modelo de IA para el idioma vietnamita fue más desafiador que nuestros tifones!" añade antes de explicar los obstáculos enfrentados durante el proceso de desarrollo.
El vietnamita es un idioma tonal con seis tonos distintos. Como es evidente en el ejemplo anterior de “ma”, pequeños matices en la vocalización pueden alterar drásticamente el significado de las palabras. Por lo tanto, era necesario un enfoque meticuloso y detallado.
"Cuando se desglosan palabras que suenan similares, una palabra consta de varios segmentos cortos o 'conjuntos de cuadros'", dice Bui Ngoc Tung, líder de ASR en SRV. “El modelo de IA diferencia entre cuadros de audio cortos de alrededor de 20 milisegundos para reconocer qué palabras corresponden a un determinado conjunto de cuadros consecutivos. Como tal, es fundamental poner un gran esfuerzo en las primeras etapas del proceso de aprendizaje de la IA”.

Además, los homófonos y los homónimos son comunes en vietnamita. Normalmente, las personas pueden confiar en el contexto y los elementos no verbales en las conversaciones para diferenciar entre palabras que suenan o que se escriben igual, pero tienen significados diferentes. Sin embargo, es necesario enseñar a los modelos de IA a identificar y diferenciar con precisión entre tonos y palabras similares.
"Esta no es una tarea sencilla", explica Thái. "Aparte de la cantidad, los datos deben ser precisos para garantizar que sean capaces de reconocer los matices lingüísticos que existen en vietnamita".

Preparación rigurosa
El proceso de refinamiento de datos consta de tres pasos. Primero, se deben revisar y corregir el audio y el texto utilizados para entrenar el modelo de IA. Luego, este conjunto de datos pasa por controles aleatorios de calidad general. Finalmente, el conjunto de datos se normaliza y limpia antes de su uso en el entrenamiento.
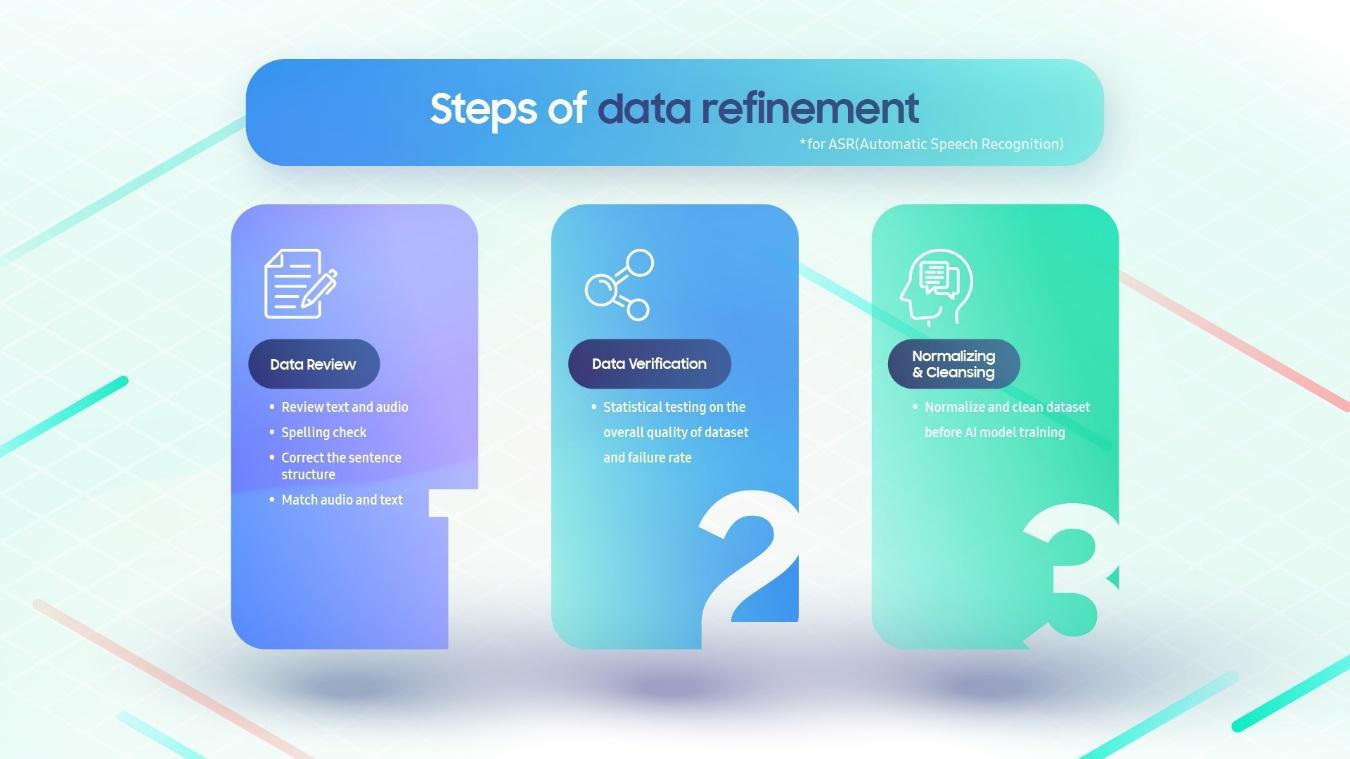
"Realizamos minuciosamente una serie de pruebas para comprobar la precisión de nuestro conjunto de datos", afirma Nguyen Manh Duy, líder de TTS en SRV, quien supervisa la creación de bases de datos. “Nos enfrentamos a una serie de problemas inesperados, como palabras mal escritas en los guiones y ruido de fondo o pronunciación incorrecta durante las grabaciones de audio. Dedicamos mucho tiempo a perfeccionar y mejorar nuestros datos de entrenamiento”.

Además de los desafíos lingüísticos únicos del vietnamita, existe una falta de datos universalmente accesibles en comparación con los idiomas más hablados. "Ésta es otra razón por la que la etapa de refinamiento de los datos es tan importante", añade. “Como teníamos fuentes limitadas, cada dato tenía que ser totalmente fiable. No había margen de error”.

Además, el modelo de IA para vietnamita debe considerar diferencias tanto de tono como regionales. Para mejorar la precisión del modelo de IA, el equipo recopiló grandes cantidades de datos con los acentos del norte, centro y sur de Vietnam, lo que resultó en una enorme cantidad de información para refinar y verificar.
Mejora continua
Los desarrolladores de SRV completaron el proyecto después de meses de arduo trabajo y el vietnamita se convirtió en uno de los primeros idiomas admitidos por Galaxy AI. A pesar de este éxito, el equipo trabaja incesantemente para mejorar la experiencia con el idioma.
"Seguimos mejorando el modelo de IA incorporando comentarios de los usuarios sobre la relevancia de las palabras y frases en Galaxy AI", dice Tran Tuan Minh, líder del proyecto de desarrollo del lenguaje de IA en SRV. "Acabamos de dar nuestros primeros pasos hacia un mundo más abierto y tenemos mucho más que explorar juntos".

En el próximo episodio de La Curva del Aprendizaje, nos dirigiremos a China para profundizar en cómo se entrenan y ajustan los modelos de IA.